
Nvidia, a leading technology company specializing in graphics processing units (GPUs), has unveiled its latest innovation: Chat With RTX. This free, personalized AI chatbot is designed to run directly on Windows PCs equipped with NVIDIA GeForce RTX 30 or 40 Series GPUs, provided they have at least 8GB of VRAM.
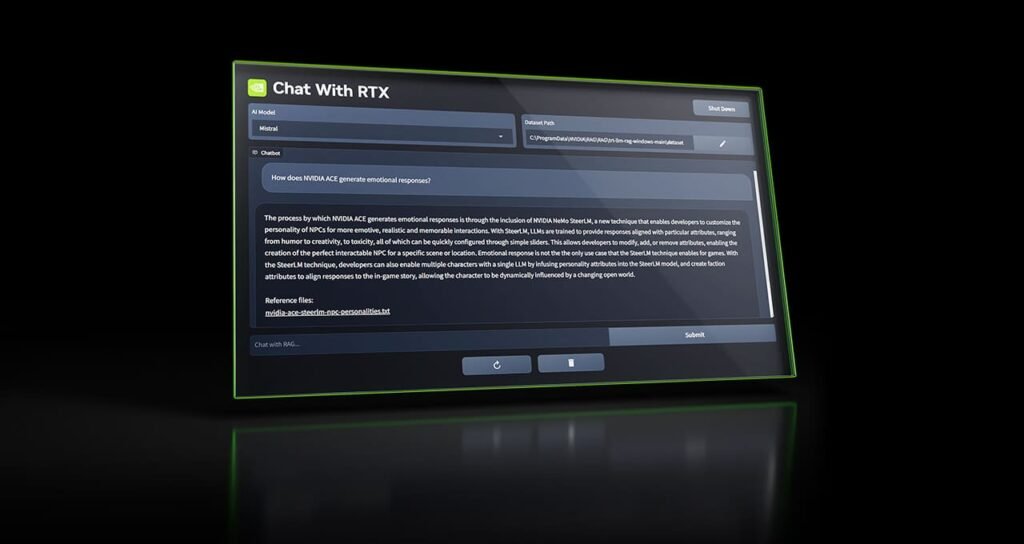
What Is Chat With RTX?
Chat With RTX leverages cutting-edge technology to bring generative AI capabilities directly to users’ devices. Here are the key features:
- Local Execution: Unlike cloud-based chatbots, Chat With RTX operates locally on your PC. This means you can enjoy AI-powered conversations without relying on an internet connection.
- Mistral and Llama LLMs: The chatbot utilizes open-source large language models (LLMs) such as Mistral and Llama 2. These LLMs enable contextually relevant answers by searching through local files on your computer.
- Retrieval-Augmented Generation (RAG): Chat With RTX combines retrieval and generation techniques to provide accurate and informative responses. It can quickly retrieve relevant information from local files and generate context-aware answers.
- Avoiding Sensitive Topics: The Mistal-7B model, which powers Chat With RTX, includes built-in conditioning to avoid certain sensitive topics. Users can engage in discussions without encountering content related to sex or violence.
How Does It Work?
- File-Based Conversations: Users can easily connect their local files as a dataset for Chat With RTX. Whether it’s a .TXT, .PDF, .DOCX, or .XML file, the chatbot scans and processes the content to answer queries.
- YouTube Integration: Chat With RTX goes beyond text files. It allows users to incorporate information from YouTube videos and playlists. This feature enriches its knowledge base without requiring an internet connection.
- Quick and Contextual Answers: By leveraging NVIDIA TensorRT-LLM software and RTX acceleration, Chat With RTX responds swiftly to user queries. Whether you need a summary, analysis, or general information, the chatbot has you covered.
The Future of Local AI Chatbots
Chat With RTX represents a significant step toward empowering users with AI capabilities directly on their PCs. As technology continues to evolve, we can expect more innovations that enhance our interactions with intelligent systems.
Now, let’s take a closer look at this locally-executed marvel and explore its features, quirks, and potential impact.
Behind the Scenes: The Technical Details
File Size and Installation
When you download Chat With RTX, be prepared for a hefty file size. The distribution package weighs in at approximately 35 gigabytes. Why so large? Well, it includes the Mistral and Llama LLM weights files—the neural network parameters that represent the knowledge learned during the AI training process. These files are essential for the chatbot’s functionality.
During installation, Chat With RTX fetches additional files, setting the stage for its local execution. But here’s where things get interesting: the chatbot runs in a console window using Python, while its interface pops up in your web browser. It’s a fusion of old-school command-line vibes and modern web-based convenience.
Layered Dependencies and the Bumpy Road
Our tests on an RTX 3060 with 12GB of VRAM revealed some bumps in the road. Like many open-source large language model (LLM) interfaces, Chat With RTX is a tangled web of dependencies. It relies on Python, CUDA, TensorRT, and more. Unfortunately, Nvidia hasn’t cracked the code for a seamless, foolproof installation process. Instead, it’s a rough-around-the-edges solution that feels like an Nvidia skin over other local LLM interfaces (such as GPT4ALL).
However, let’s give credit where it’s due: the fact that this capability comes directly from Nvidia is noteworthy. It signals a commitment to empowering users with AI capabilities right on their personal devices.
Privacy and Performance: The Trade-offs
Privacy Wins
One massive advantage of local processing is user privacy. Unlike cloud-based services (looking at you, ChatGPT), Chat With RTX doesn’t transmit sensitive data over the internet. Your conversations stay within the confines of your PC, providing peace of mind.
Performance Considerations
Chat With RTX uses the Mistral 7B model, which feels akin to early 2022-era GPT-3. Considering it runs on a consumer GPU, that’s impressive. However, it’s not a true ChatGPT replacement—yet. It can’t hold a candle to the processing prowess of GPT-4 Turbo or Google Gemini Pro/Ultra. But hey, it’s a step in the right direction.
Get Chat With RTX Today!
Nvidia GPU owners, rejoice! You can download Chat With RTX for free from the official Nvidia website. Dive into local AI conversations, explore your files, and witness the future unfold right on your desktop.
Stay tuned for updates as Nvidia continues to push the boundaries of AI and GPU technology. The journey has just begun!
For more details and to download Chat With RTX, visit the official Nvidia blog post.
Stay tuned for further updates as Nvidia continues to push the boundaries of AI and GPU technology!

